刷题回顾
现在我已经刷完hot 100 了,二刷开始记笔记+速记了呜呜呜
题目描述
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
1 2 3 输入:nums = [100,4,200,1,3,2] 输出:4 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
1 2 输入:nums = [0,3,7,2,5,8,4,6,0,1] 输出:9
示例 3:
1 2 输入:nums = [1,0,1,2] 输出:3
提示:
0 <= nums.length <= 105-109 <= nums[i] <= 109
题解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public : int longestConsecutive (vector<int >& nums) unordered_set<int > setNums; for (const auto & num : nums) { setNums.insert (num); } int ans = 0 ; int curLen = 1 ; for (const auto & num : setNums) { int curNum = num; if (!setNums.count (curNum - 1 )) { curLen = 1 ; while (setNums.count (curNum + 1 )) { curNum++; curLen++; } } ans = max (ans, curLen); } return ans; } };
[!IMPORTANT]
注意不要超时,遍历的时候遍历set 而不是原数组,第二次做遍历数组导致超时
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
1 2 3 输入:nums = [100,4,200,1,3,2] 输出:4 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
1 2 输入:nums = [0,3,7,2,5,8,4,6,0,1] 输出:9
示例 3:
1 2 输入:nums = [1,0,1,2] 输出:3
提示:
0 <= nums.length <= 105-109 <= nums[i] <= 109
题解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public : void moveZeroes (vector<int >& nums) int n = nums.size (), left = 0 , right = 0 ; while (right < n) { if (nums[right]) { swap (nums[left], nums[right]); left++; } right++; } } };
[!IMPORTANT]
速记:left 就是个记录非0的插桩,right外后走找非0,如果right 非0,把数插进去,left++ 且 right++; 否则 right++继续找非0
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请你返回所有和为 0 且不重复的三元组。
**注意:**答案中不可以包含重复的三元组。
示例 1:
1 2 3 4 5 6 7 8 输入:nums = [-1,0,1,2,-1,-4] 输出:[[-1,-1,2],[-1,0,1]] 解释: nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。 nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。 nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。 不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。 注意,输出的顺序和三元组的顺序并不重要。
示例 2:
1 2 3 输入:nums = [0,1,1] 输出:[] 解释:唯一可能的三元组和不为 0 。
示例 3:
1 2 3 输入:nums = [0,0,0] 输出:[[0,0,0]] 解释:唯一可能的三元组和为 0 。
题解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class Solution {public : vector<vector<int >> threeSum (vector<int >& nums) { sort (nums.begin (), nums.end ()); int n = nums.size (); vector<vector<int >> ans; for (int i=0 ; i<n-2 ; ++i) { if (nums[i] > 0 ) break ; if (i>0 && nums[i] == nums[i - 1 ]) continue ; int L = i + 1 ; int R = n - 1 ; while (L < R) { int sum = nums[i] + nums[L] + nums[R]; if (sum < 0 ){ L++; } else if (sum > 0 ){ R--; } else { ans.push_back ({nums[i], nums[L], nums[R]}); while (L < R && nums[L] == nums[L + 1 ]) L++; while (L < R && nums[R] == nums[R - 1 ]) R--; L++; R--; } } } return ans; } };
[!IMPORTANT]
速记:三数之和,上来先排序,排序后内循环注意提前终止、去重逻辑 以及 双指针收缩空间! $$O(n^2)$$ 时间复杂度
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:
1 2 3 输入:height = [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2:
1 2 输入:height = [4,2,0,3,2,5] 输出:9
提示:
n == height.length1 <= n <= 2 * 1040 <= height[i] <= 105
题解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public : int trap (vector<int >& height) int ans = 0 ; int left = 0 , right = height.size () - 1 ; int leftMax = 0 , rightMax = 0 ; while (left <= right) { leftMax = max (leftMax, height[left]); rightMax = max (rightMax, height[right]); if (leftMax <= rightMax){ ans += leftMax - height[left]; left++; } else { ans += rightMax - height[right]; right--; } } return ans; } };
[!IMPORTANT]
不要在if里面更新 leftmax, 可能越界,请在每次while每次进去的时候更新,所以leftMax, rightMax 初始化都是0,而不是 height[0] height[n - 1]
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
子数组是数组中元素的连续非空序列。
示例 1:
1 2 输入:nums = [1,1,1], k = 2 输出:2
示例 2:
1 2 输入:nums = [1,2,3], k = 3 输出:2
提示:
1 <= nums.length <= 2 * 104-1000 <= nums[i] <= 1000-107 <= k <= 107
题解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <vector> #include <unordered_map> using namespace std;int subarraySum (vector<int >& nums, int k) unordered_map<int , int > prefix_counts; prefix_counts[0 ] = 1 ; int current_sum = 0 ; int ans = 0 ; for (int i=0 ; i<nums.size (); ++i) { current_sum += nums[i]; int target = current_sum - k; if (prefix_counts.find (target) != prefix_counts.end ()) { ans += prefix_counts[target]; } prefix_counts[current_sum]++; } return ans; }
看到这题就是前缀和,一定要记得前缀和的定义,以及为了缩减时间复杂度,这里要用哈希表存一路上的结果,包括两数之和,最后一行代码一定是保存某种哈希
LTC 560 变体,找到最短的满足和为k的子数组
如果要求找到最短的,那么我们的哈希就是要一路上存这个最近的索引,因此我们把 prefix_counts 变成 prefix_order 其中order代表 一直到第几个数 (从1开始)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <vector> #include <algorithm> #include <unordered_map> #include <climits> using namespace std;int minSubArrayLenK (vector<int >& nums, int k) unordered_map<int , int > prefix_order; prefix_order[0 ] = 0 ; int current_sum = 0 ; int ans = INT_MAX; for (int j = 1 ; j <= nums.size (); ++j) { current_sum += nums[j - 1 ]; int target = current_sum - k; if (prefix_order.count (target)) { ans = min (ans, j - prefix_order[target]); } prefix_order[current_sum] = j; } return (ans == INT_MAX) ? 0 : ans; }
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回 滑动窗口中的最大值 。
示例 1:
1 2 3 4 5 6 7 8 9 10 11 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3 输出:[3,3,5,5,6,7] 解释: 滑动窗口的位置 最大值 --------------- ----- [1 3 -1] -3 5 3 6 7 3 1 [3 -1 -3] 5 3 6 7 3 1 3 [-1 -3 5] 3 6 7 5 1 3 -1 [-3 5 3] 6 7 5 1 3 -1 -3 [5 3 6] 7 6 1 3 -1 -3 5 [3 6 7] 7
示例 2:
1 2 输入:nums = [1], k = 1 输出:[1]
提示:
1 <= nums.length <= 105-104 <= nums[i] <= 1041 <= k <= nums.length
题解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <deque> #include <vector> using namespace std;class Solution {public : vector<int > maxSlidingWindow (vector<int >& nums, int k) { deque<int > dq; vector<int > ans; for (int i=0 ; i<nums.size (); ++i) { while (!dq.empty () && nums[dq.back ()] <= nums[i]){ dq.pop_back (); } dq.push_back (i); if (dq.front () == i - k) { dq.pop_front (); } if ( i >= k - 1 ) { ans.push_back (nums[dq.front ()]); } } return ans; } };
[!IMPORTANT]
这一题本质上就是让我们去做一个单调队列,这里 for 循环里面每一次有新的数据来,首先看看这些队列后面排的数,有一个算一个,如果比新要加入的还要小,那么可以删了这些了,因为这些不是决定当前窗口的值; 并且实时注意队列头的那个最大值,如果它的索引是已经不在窗口了,记得pop出去
给定两个字符串 s 和 t,长度分别是 m 和 n,返回 s 中的 最短窗口 子串 ,使得该子串包含 t 中的每一个字符(包括重复字符 )。如果没有这样的子串,返回空字符串 ""。
测试用例保证答案唯一。
示例 1:
1 2 3 输入:s = "ADOBECODEBANC", t = "ABC" 输出:"BANC" 解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。
示例 2:
1 2 3 输入:s = "a", t = "a" 输出:"a" 解释:整个字符串 s 是最小覆盖子串。
示例 3:
1 2 3 4 输入: s = "a", t = "aa" 输出: "" 解释: t 中两个字符 'a' 均应包含在 s 的子串中, 因此没有符合条件的子字符串,返回空字符串。
提示:
m == s.lengthn == t.length1 <= m, n <= 105s 和 t 由英文字母组成
**进阶:**你能设计一个在 O(m + n) 时间内解决此问题的算法吗?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <unordered_map> #include <string> #include <climits> using namespace std;string minWindow (string s, string t) unordered_map<char , int > need, window; int valid = 0 ; int left = 0 , right = 0 ; int min_len = INT_MAX, start = 0 ; for (char c : t) need[c]++; while (right < s.size ()) { char c = s[right]; right++; if (need.count (c)) { window[c]++; if (window[c] == need[c]) { valid++; } } while (valid == need.size ()) { if (right - left < min_len) { start = left; min_len = right - left; } char d = s[left]; left++; if (need.count (d)) { if (window[d] == need[d]) { valid--; } window[d]--; } } } return min_len == INT_MAX ? "" : s.substr (start, min_len); }
[!IMPORTANT]
口诀:右移找齐全,齐全就缩左,缩前先记录最优值
想要提升速率,直接换成 固定长的数组即可
计算机中的每一个字符(英文字母、数字、标点符号、空格等)都对应一个整数编号:
数字 0-9 :对应 48-57大写字母 A-Z :对应 65-90小写字母 a-z :对应 97-122
设置定长数组,长度为128即可
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组 是数组中的一个连续部分。
示例 1:
1 2 3 输入:nums = [-2,1,-3,4,-1,2,1,-5,4] 输出:6 解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
示例 2:
示例 3:
1 2 输入:nums = [5,4,-1,7,8] 输出:23
提示:
1 <= nums.length <= 105-104 <= nums[i] <= 104
**进阶:**如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的 分治法 求解。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <vector> #include <algorithm> #include <climits> using namespace std;class Solution {public : int maxSubArray (vector<int >& nums) int n = nums.size (); int ans = INT_MIN; int curr = 0 ; for (int i = 0 ; i<n; ++i) { curr += nums[i]; ans = max (ans, curr); if (curr < 0 ) { curr = 0 ; } } return ans; } };
[!IMPORTANT]
这一题一眼贪心, 如果当前和小于0,那么就抛弃前面的,重新开始计数,每次更新最大值即可
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
示例 1:
1 2 3 输入:intervals = [[1,3],[2,6],[8,10],[15,18]] 输出:[[1,6],[8,10],[15,18]] 解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
1 2 3 输入:intervals = [[1,4],[4,5]] 输出:[[1,5]] 解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
示例 3:
1 2 3 输入:intervals = [[4,7],[1,4]] 输出:[[1,7]] 解释:区间 [1,4] 和 [4,7] 可被视为重叠区间。
提示:
1 <= intervals.length <= 104intervals[i].length == 20 <= starti <= endi <= 104
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <vector> #include <algorithm> using namespace std;class Solution {public : vector<vector<int >> merge (vector<vector<int >>& intervals) { sort (intervals.begin (), intervals.end ()); vector<vector<int >> ans; ans.push_back (intervals[0 ]); for (int i=1 ; i<intervals.size (); ++i) { int & lastR = ans.back ()[1 ]; int currL = intervals[i][0 ]; int currR = intervals[i][1 ]; if (currL <= lastR) { lastR = max (lastR, currR); } else { ans.push_back (intervals[i]); } } return ans; } };
[!IMPORTANT]
精髓在于利用 int& 来修改这个ans里面的元素,没有什么繁杂的下标索引
给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。
示例 1:
1 2 3 4 5 6 输入: nums = [1,2,3,4,5,6,7], k = 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,2,3,4,5] 向右轮转 3 步: [5,6,7,1,2,3,4]
示例 2:
1 2 3 4 5 输入:nums = [-1,-100,3,99], k = 2 输出:[3,99,-1,-100] 解释: 向右轮转 1 步: [99,-1,-100,3] 向右轮转 2 步: [3,99,-1,-100]
提示:
1 <= nums.length <= 105-231 <= nums[i] <= 231 - 10 <= k <= 105
进阶:
尽可能想出更多的解决方案,至少有 三种 不同的方法可以解决这个问题。
你可以使用空间复杂度为 O(1) 的 原地 算法解决这个问题吗?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <vector> #include <algorithm> using namespace std;class Solution {public : void rotate (vector<int >& nums, int k) int n = nums.size (); k = k % n; reverse (nums.begin (), nums.end ()); reverse (nums.begin (), nums.begin () + k); reverse (nums.begin () + k, nums.end ()); } };
[!IMPORTANT]
第二种写法,即 多个单独的 置换环,就像抢椅子一样,正常的数学思维,但是数学上优雅不代表工程上最优,上面的这个解答就是缓存友好的
具体有多少置换环: gcd(n, k) 找最大公约数, for循环里面套 do{}while(); 连续替换即可
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除了 nums[i] 之外其余各元素的乘积 。
题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请 **不要使用除法,**且在 O(n) 时间复杂度内完成此题。
示例 1:
1 2 输入: nums = [1,2,3,4] 输出: [24,12,8,6]
示例 2:
1 2 输入: nums = [-1,1,0,-3,3] 输出: [0,0,9,0,0]
提示:
2 <= nums.length <= 105-30 <= nums[i] <= 30输入 保证 数组 answer[i] 在 32 位 整数范围内
**进阶:**你可以在 O(1) 的额外空间复杂度内完成这个题目吗?( 出于对空间复杂度分析的目的,输出数组 不被视为 额外空间。)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <vector> using namespace std;class Solution {public : vector<int > productExceptSelf (vector<int >& nums) { int n = nums.size (); vector<int > ans (n, 1 ) ; vector<int > left (n, 1 ) ; vector<int > right (n, 1 ) ; for (int i=1 ; i<n; ++i) { left[i] = nums[i-1 ] * left[i-1 ]; } for (int i=n-2 ; i>=0 ; --i) { right[i] = right[i+1 ] * nums[i+1 ]; } for (int i=0 ; i<n; ++i) { ans[i] = left[i] * right[i]; } return ans; } };
O(n), O(n) 做法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <vector> using namespace std;class Solution {public : vector<int > productExceptSelf (vector<int >& nums) { int n = nums.size (); vector<int > ans (n, 1 ) ; for (int i=n-2 ; i>=0 ; --i) { ans[i] = ans[i+1 ] * nums[i+1 ]; } int curr = 1 ; for (int i=1 ; i<n; ++i) { curr *= nums[i - 1 ]; ans[i] *= curr; } return ans; } };
[!IMPORTANT]
这种做法就是O(n)的空间复杂度(用两个数组分别表示这个位置左边的累乘和右边的累乘),我们想要变成O(1)空间复杂度,很简单,就是在原有的基础上,我们把正确的答案先放到这个 ans里面, 然后就用一个额外的变量存储左边的累乘结果即可
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。
请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。
示例 1:
1 2 3 输入:nums = [1,2,0] 输出:3 解释:范围 [1,2] 中的数字都在数组中。
示例 2:
1 2 3 输入:nums = [3,4,-1,1] 输出:2 解释:1 在数组中,但 2 没有。
示例 3:
1 2 3 输入:nums = [7,8,9,11,12] 输出:1 解释:最小的正数 1 没有出现。
提示:
1 <= nums.length <= 105-231 <= nums[i] <= 231 - 1
一开始的想法自然肯定是这样:我们找一个 bool 数组,来存放这些数,比如 数字1,就要在位置0, [1,2,3,4,5] 这些都在对应的位置上面,所以我们有这样的写法,这样,我们只需要检查bool数组里面,第一个0,就知道哪个数是最小的没有出现的了。
但是题目要求用常数空间来做,那么这样就无非是在原本的数组上面进行操作,上面提到的bool数组的做法,无非就是哈希表的一种,所以我们可以这样,如果这个数,不在其应该在的位置**(前提是这个数可以放置,如果是负数,或者较大的正数,总而言之就是超出数组索引范围的数),那么我们就进行交换,并且继续检查交换后的数(因此我们用while循环来做)**
这样就显而易见了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <vector> using namespace std;class Solution {public : int firstMissingPositive (vector<int >& nums) int n = nums.size (); for (int i = 0 ; i < n; ++i) { while (nums[i] > 0 && nums[i] <= n && nums[i] != nums[nums[i] - 1 ]) { swap (nums[i], nums[nums[i] - 1 ]); } } for (int i = 0 ; i < n; ++i) { if (nums[i] != i + 1 ) { return i + 1 ; } } return n + 1 ; } };
[!IMPORTANT]
我们遵循的索引规范,我们认为这样的数组是一个都在自己该有的位置上面的数组: [1, 2, 3, 4, 5] 因此我们有数字 i对应的索引位置就是 i-1
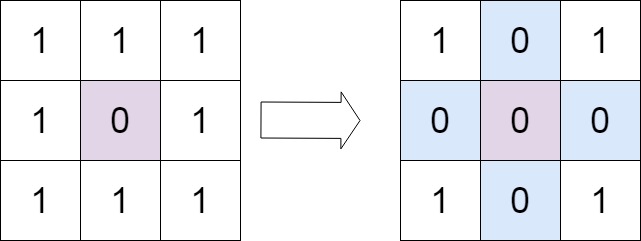
给定一个 *m* x *n* 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地
示例 1:
1 2 输入:matrix = [[1,1,1],[1,0,1],[1,1,1]] 输出:[[1,0,1],[0,0,0],[1,0,1]]
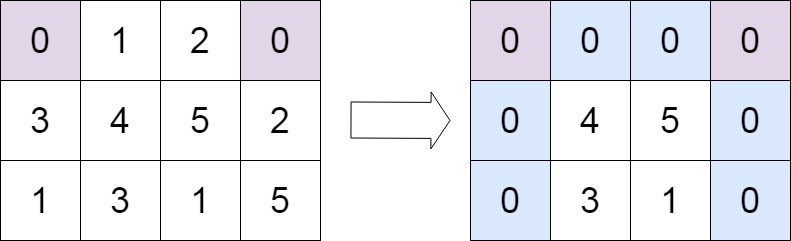
示例 2:
1 2 输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]] 输出:[[0,0,0,0],[0,4,5,0],[0,3,1,0]]
提示:
m == matrix.lengthn == matrix[0].length1 <= m, n <= 200-231 <= matrix[i][j] <= 231 - 1
进阶:
一个直观的解决方案是使用 O(*m**n*) 的额外空间,但这并不是一个好的解决方案。
一个简单的改进方案是使用 O(*m* + *n*) 的额外空间,但这仍然不是最好的解决方案。
你能想出一个仅使用常量空间的解决方案吗?
正常的想法如下: 用两个 unordered_set 去存row 和 col, 具体对应的哪一个是可以赋值为0的,然后再一次双层循环去赋值,具体的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <vector> using namespace std;class Solution {public : void setZeroes (vector<vector<int >>& matrix) unordered_set<int > row, col; int m = matrix.size (); int n = matrix[0 ].size (); for (int i=0 ; i<m; ++i) { for (int j=0 ; j<n; ++j) { if (matrix[i][j] == 0 ) { row.insert (i); col.insert (j); } } } for (int i=0 ; i<m; ++i) { for (int j=0 ; j<n; ++j) { if (row.count (i) || col.count (j)) { matrix[i][j] = 0 ; } } } } };
但是这样的做法空间复杂度是不符合要求的,所以我们还是借用本身的空间,不使用 unordered_set 去存这个信息,我们借用这个矩阵的第一行和第一列去存储这一行的信息,如果这一列要置为0,那么这一列的开头也就是 matrix[0][j] = 0
但是这样的话,我们并不知道,这里的第一行和第一列是否要置为0,所以我们要多用两个bool 变量,来确定这里的第一行和第一列是不是需要被全置为0
因此代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <vector> using namespace std;class Solution {public : void setZeroes (vector<vector<int >>& matrix) bool row0 = 0 , col0 = 0 ; int m = matrix.size (), n = matrix[0 ].size (); for (int i=0 ; i<m; ++i) if (matrix[i][0 ] == 0 ) col0 = 1 ; for (int j=0 ; j<n; ++j) if (matrix[0 ][j] == 0 ) row0 = 1 ; for (int i=1 ; i<m; ++i) { for (int j=1 ; j<n; ++j) { if (matrix[i][j] == 0 ) { matrix[i][0 ] = 0 ; matrix[0 ][j] = 0 ; } } } for (int i=1 ; i<m; ++i) { for (int j=1 ; j<n; ++j) { if (matrix[i][0 ] == 0 || matrix[0 ][j] == 0 ) { matrix[i][j] = 0 ; } } } if (col0) for (int i=0 ; i<m; ++i) matrix[i][0 ] = 0 ; if (row0) for (int j=0 ; j<n; ++j) matrix[0 ][j] = 0 ; } };
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
示例 1:
1 2 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5]
示例 2:
1 2 输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]] 输出:[1,2,3,4,8,12,11,10,9,5,6,7]
提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 10-100 <= matrix[i][j] <= 100
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <vector> using namespace std;class Solution {public : vector<int > spiralOrder (vector<vector<int >>& matrix) { if (matrix.empty ()) return {}; int up = 0 , down = matrix.size () -1 ; int left = 0 , right = matrix[0 ].size () - 1 ; vector<int > ans; while (true ) { for (int i=left; i<=right; ++i) ans.push_back (matrix[up][i]); if (++up > down) break ; for (int i=up; i<=down; ++i) ans.push_back (matrix[i][right]); if (--right < left) break ; for (int i=right; i>=left; --i) ans.push_back (matrix[down][i]); if (--down < up) break ; for (int i=down; i>=up; --i) ans.push_back (matrix[i][left]); if (++left > right) break ; } return ans; } };
[!IMPORTANT]
为了避免之前的那种定义长度为4的方向数组,导致边界问题重复debug,这里使用简单易懂的逻辑,直接这样想象成4堵墙,每次遍历完成之后,我们就把对应方向的墙收缩,注意我们这里的四个break,以及++操作,四个break必须存在,否则会导致重复遍历。
给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在** 原地 ** 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。
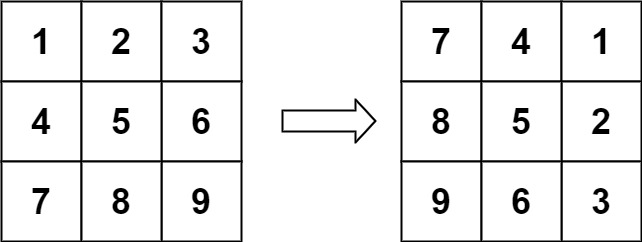
示例 1:
1 2 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]] 输出:[[7,4,1],[8,5,2],[9,6,3]]
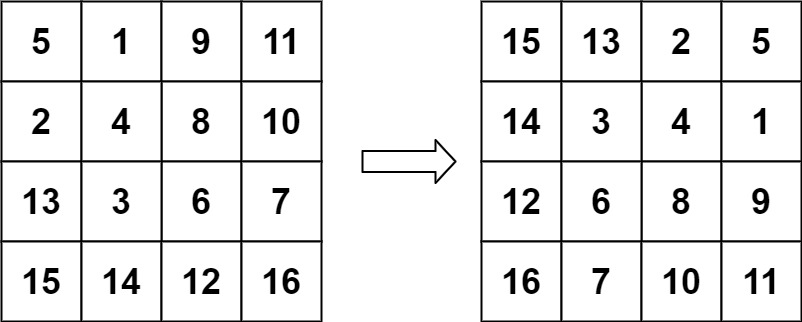
示例 2:
1 2 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]] 输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]]
提示:
n == matrix.length == matrix[i].length1 <= n <= 20-1000 <= matrix[i][j] <= 1000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public : void rotate (vector<vector<int >>& matrix) for (int i=0 ; i<matrix.size (); ++i) { for (int j=0 ; j<i; ++j) { swap (matrix[i][j], matrix[j][i]); } } for (int i=0 ; i<matrix.size (); ++i) { reverse (matrix[i].begin (), matrix[i].end ()); } } };
[!IMPORTANT]
先交换正对角线,再reverse即可
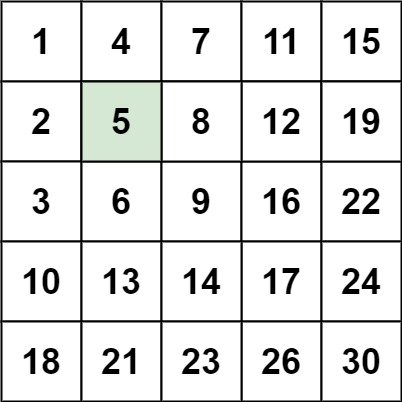
编写一个高效的算法来搜索 *m* x *n* 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
每行的元素从左到右升序排列。
每列的元素从上到下升序排列。
示例 1:
1 2 输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5 输出:true
示例 2:
1 2 输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 20 输出:false
提示:
m == matrix.lengthn == matrix[i].length1 <= n, m <= 300-109 <= matrix[i][j] <= 109每行的所有元素从左到右升序排列
每列的所有元素从上到下升序排列
-109 <= target <= 109
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public : bool searchMatrix (vector<vector<int >>& matrix, int target) int n = matrix.size (), m = matrix[0 ].size (); int row = 0 , col = m-1 ; while (row < n && col>=0 ) { if (target == matrix[row][col]) { return true ; } else if (target < matrix[row][col]) { col--; } else { row++; } } return false ; } };
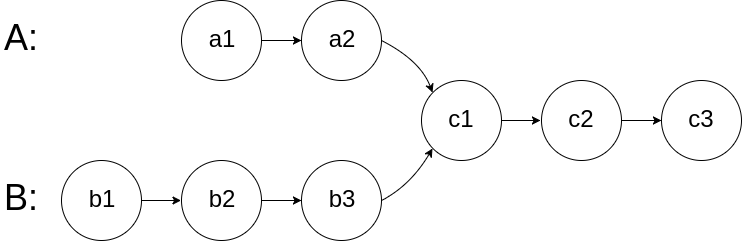
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交**:**
题目数据 保证 整个链式结构中不存在环。
注意 ,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0listA - 第一个链表listB - 第二个链表skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例 1:
1 2 3 4 5 6 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3 输出:Intersected at '8' 解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。 从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。 在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。 — 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
示例 2:
1 2 3 4 5 输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1 输出:Intersected at '2' 解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。 从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。 在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
1 2 3 4 5 输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2 输出:No intersection 解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。 由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。 这两个链表不相交,因此返回 null 。
提示:
listA 中节点数目为 mlistB 中节点数目为 n1 <= m, n <= 3 * 1041 <= Node.val <= 1050 <= skipA <= m0 <= skipB <= n如果 listA 和 listB 没有交点,intersectVal 为 0
如果 listA 和 listB 有交点,intersectVal == listA[skipA] == listB[skipB]
**进阶:**你能否设计一个时间复杂度 O(m + n) 、仅用 O(1) 内存的解决方案?
这道题要抓住一个精髓:如果两个链表相交,那么这个两个链表一定有一段相同的长度的,所以我们只需要想办法让这俩从同一个起点出发,并且后面的长度相同即可。
这里先给出一个结果不太好的写法:(都是一样的时间复杂度,但是这个循环遍历次数要多)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 class Solution {public : ListNode *getIntersectionNode (ListNode *headA, ListNode *headB) { int lenA = 0 , lenB = 0 ; ListNode *Ap = headA, *Bp = headB; while (Ap != nullptr ) { lenA++; Ap = Ap->next; } while (Bp != nullptr ) { lenB++; Bp = Bp->next; } Ap = headA; Bp = headB; if (lenA > lenB) { while (lenA != lenB) { Ap = Ap->next; lenA--;} } else { while (lenA != lenB) { Bp = Bp->next; lenB--;} } while (Ap != nullptr ) { if (Ap == Bp) { return Ap; } else { Ap = Ap->next; Bp = Bp->next; } } return nullptr ; } };
然后我们给出浪漫相遇方法,即如果你走过我走过的路,我们终会相遇。
假设 A 链表非相交部分长度为 a a a b b b c c c
pA 走过的总路程:a + c + b a + c + b a + c + b pB 走过的总路程:b + c + a b + c + a b + c + a 它们走过的总长度是一模一样的 !所以在第二轮时,它们一定会同时到达相交点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public : ListNode *getIntersectionNode (ListNode *headA, ListNode *headB) { if (headA == nullptr || headB == nullptr ) { return nullptr ; } ListNode* pA = headA, *pB = headB; while (pA != pB) { pA = (pA == nullptr ) ? headB : pA->next; pB = (pB == nullptr ) ? headA : pB->next; } return pA; } };
[!IMPORTANT]
这个方法巧妙在,其最后一定会退出,也就是公共区域我们把 nullptr 也作为公共区域,那么while循环就一定会退出
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
1 2 输入:head = [1,2,3,4,5] 输出:[5,4,3,2,1]
示例 2:
1 2 输入:head = [1,2] 输出:[2,1]
示例 3:
提示:
链表中节点的数目范围是 [0, 5000]
-5000 <= Node.val <= 5000
**进阶:**链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public : ListNode* reverseList (ListNode* head) { ListNode *prev = nullptr ; ListNode *curr = head; while (curr != nullptr ) { ListNode *nextTemp = curr->next; curr->next = prev; prev = curr; curr = nextTemp; } return prev; } };
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
示例 1:
1 2 输入:head = [1,2,2,1] 输出:true
示例 2:
1 2 输入:head = [1,2] 输出:false
提示:
链表中节点数目在范围[1, 105] 内
0 <= Node.val <= 9
**进阶:**你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class Solution {public : bool isPalindrome (ListNode* head) if (head == nullptr || head->next == nullptr ) return true ; ListNode *slow = head, *fast = head; while (fast->next != nullptr && fast->next->next != nullptr ) { slow = slow->next; fast = fast->next->next; } ListNode *prev = nullptr ; ListNode *curr = slow->next; while (curr != nullptr ) { ListNode *next = curr->next; curr->next = prev; prev = curr; curr = next; } bool ans = true ; ListNode *p1 = head; ListNode *p2 = prev; while (p2 != nullptr ) { if (p1->val != p2->val) { ans = false ; break ; } p1 = p1->next; p2 = p2->next; } return ans; } };
[!IMPORTANT]
想清楚三个问题:
快慢指针在链表里面怎么写?需不需要dummy head?----------> 不需要dummy head,但是循环条件必须这样写: while(fast->next != nullptr && fast->next->next != nullptr) 这样能保证慢指针要么停在奇数链表的中点,要么停在偶数链表的前半部分的最后一个节点。(如果写成while (fast != nullptr && fast->next != nullptr) 对于链表[1,2,3,4]会被切成 1, 2, 3 和 4)
怎么判断切分后的两个链表相等或者一致? --------> 一定是按照后半程去比较,比如奇数 [1,2,3,2,1] ----> [1,2,3] 和 [2, 1] 我们一定是按照短的来,所以是通过后半程去进行对比即可
可能你会关心: [1,2] 这种,可能fast指针就是null了,那怎么办?记住,这个时候,我们翻转的数组是从 slow->next 开始的,也就是我们最终还是会变成[1] 和 [2] 。也就是说,不要去关系 fast指针,fast指针不参与链表划分,我们想要的是那个中间位置,也就是slow指针。
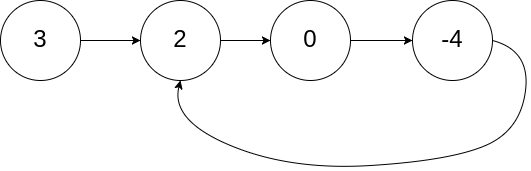
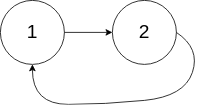
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:
1 2 3 输入:head = [3,2,0,-4], pos = 1 输出:true 解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
1 2 3 输入:head = [1,2], pos = 0 输出:true 解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
1 2 3 输入:head = [1], pos = -1 输出:false 解释:链表中没有环。
提示:
链表中节点的数目范围是 [0, 104]
-105 <= Node.val <= 105pos 为 -1 或者链表中的一个 有效索引 。
**进阶:**你能用 O(1)(即,常量)内存解决此问题吗?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {public : bool hasCycle (ListNode *head) if (head == nullptr || head->next == nullptr ) { return false ; } ListNode *slow = head; ListNode *fast = head; while (fast->next != nullptr && fast->next->next != nullptr ) { slow = slow->next; fast = fast->next->next; if (slow == fast) { return true ; } } return false ; } };
[!IMPORTANT]
我们看清楚了上面的回文链表,这一题就很清楚了,无非就是快慢指针,并且快指针必须这样写,while循环的判断如出一辙,只不过要注意先移动后判断。
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始 )。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递 ,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
1 2 3 输入:head = [3,2,0,-4], pos = 1 输出:返回索引为 1 的链表节点 解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
1 2 3 输入:head = [1,2], pos = 0 输出:返回索引为 0 的链表节点 解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
1 2 3 输入:head = [1], pos = -1 输出:返回 null 解释:链表中没有环。
提示:
链表中节点的数目范围在范围 [0, 104] 内
-105 <= Node.val <= 105pos 的值为 -1 或者链表中的一个有效索引
**进阶:**你是否可以使用 O(1) 空间解决此题?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class Solution {public : ListNode *detectCycle (ListNode *head) { if (head == nullptr || head->next == nullptr ) { return nullptr ; } ListNode *slow = head; ListNode *fast = head; bool hasCycle = false ; while (fast->next != nullptr && fast->next->next != nullptr ) { slow = slow->next; fast = fast->next->next; if (slow == fast) { hasCycle = true ; break ; } } if (!hasCycle) { return nullptr ; } slow = head; while (slow != fast) { slow = slow->next; fast = fast->next; } return slow; } };
[!IMPORTANT]
还是快慢指针,不过这里要有一个 bool hasCycle 值来确定是否有环,这里会出现没有环并且退出的情况,现在我们不知道 while() 到底有没有进入循环 还是 我们是从while循环里面退出了,这是两个不同的概念,如果我们没有 hasCycle 我们就不好去处理: [1 ,2] 这种无环短链表,因为while循环根本进不去,然后fast 和 slow 都停在了起始位置,所以报错!!!!
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
1 2 输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]
示例 2:
1 2 输入:l1 = [], l2 = [] 输出:[]
示例 3:
1 2 输入:l1 = [], l2 = [0] 输出:[0]
提示:
两个链表的节点数目范围是 [0, 50]
-100 <= Node.val <= 100l1 和 l2 均按 非递减顺序 排列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 class Solution {public : ListNode* mergeTwoLists (ListNode* list1, ListNode* list2) { if (list1 == nullptr ) { return list2; } if (list2 == nullptr ) { return list1; } ListNode *dummy = new ListNode (-1 ); ListNode *p = dummy; while (list1 != nullptr && list2 != nullptr ) { if (list1->val <= list2->val) { p->next = list1; list1 = list1->next; } else { p->next = list2; list2 = list2->next; } p = p->next; } if (list1 != nullptr ) { p->next = list1; } else if (list2 != nullptr ) { p->next = list2; } ListNode *ans = dummy->next; delete dummy; return ans; } };
这种写法固然没有问题,但是显得很冗余,很复杂,我们不如在栈上面开辟空间,然后去进行操作,并且我们不需要这些多余的判断,我们可以直接用 while接上后续的判断即可,这种前面的判断有些多余了。
写法应该如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public : ListNode* mergeTwoLists (ListNode* list1, ListNode* list2) { ListNode dummy (0 ) ; ListNode *p = &dummy; while (list1 != nullptr && list2 != nullptr ) { if (list1->val <= list2->val) { p->next = list1; list1 = list1->next; }else { p->next = list2; list2 = list2->next; } p = p->next; } p->next = (list1 == nullptr ) ? list2 : list1; return dummy.next; } };
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:
1 2 3 输入:l1 = [2,4,3], l2 = [5,6,4] 输出:[7,0,8] 解释:342 + 465 = 807.
示例 2:
1 2 输入:l1 = [0], l2 = [0] 输出:[0]
示例 3:
1 2 输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9] 输出:[8,9,9,9,0,0,0,1]
提示:
每个链表中的节点数在范围 [1, 100] 内
0 <= Node.val <= 9题目数据保证列表表示的数字不含前导零
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 class Solution {public : ListNode* addTwoNumbers (ListNode* l1, ListNode* l2) { int carry = 0 ; int curr = 0 ; ListNode *dummy = new ListNode (-1 ); ListNode *p = dummy; while (l1 != nullptr || l2 != nullptr ) { if (l1 != nullptr && l2 != nullptr ) { curr = l1->val + l2->val + carry; carry = curr >= 10 ? 1 : 0 ; curr = curr % 10 ; p->next = new ListNode (curr); p = p->next; l1 = l1->next; l2 = l2->next; } else if (l1 != nullptr ) { curr = l1->val + carry; carry = curr >= 10 ? 1 : 0 ; curr = curr % 10 ; p->next = new ListNode (curr); p = p->next; l1 = l1->next; } else { curr = l2->val + carry; carry = curr >= 10 ? 1 : 0 ; curr = curr % 10 ; p->next = new ListNode (curr); p = p->next; l2 = l2->next; } } if (carry) { p->next = new ListNode (carry); } ListNode *ans = dummy->next; delete dummy; return ans; } };
上面这种写法稍显臃肿,while 里面套上多个 if语句,然后出来之后又有一个判断carry的,我们不如把它都写在一起。如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public : ListNode* addTwoNumbers (ListNode* l1, ListNode* l2) { int carry = 0 ; ListNode dummy (0 ) ; ListNode *p = &dummy; while (l1 != nullptr || l2 != nullptr || carry) { int v1 = (l1 != nullptr ) ? l1->val : 0 ; int v2 = (l2 != nullptr ) ? l2->val : 0 ; int sum = v1 + v2 + carry; carry = sum / 10 ; int val = sum % 10 ; p->next = new ListNode (val); p = p->next; if (l1 != nullptr ) l1 = l1->next; if (l2 != nullptr ) l2 = l2->next; } return dummy.next; } };
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
1 2 输入:head = [1,2,3,4,5], n = 2 输出:[1,2,3,5]
示例 2:
1 2 输入:head = [1], n = 1 输出:[]
示例 3:
1 2 输入:head = [1,2], n = 1 输出:[1]
提示:
链表中结点的数目为 sz
1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz
**进阶:**你能尝试使用一趟扫描实现吗?
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
1 2 输入:head = [1,2,3,4,5], n = 2 输出:[1,2,3,5]
示例 2:
1 2 输入:head = [1], n = 1 输出:[]
示例 3:
1 2 输入:head = [1,2], n = 1 输出:[1]
提示:
链表中结点的数目为 sz
1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz
**进阶:**你能尝试使用一趟扫描实现吗?
这一题说难不难,说难也难,难在怎么去处理边界问题,怎么去写循环?快指针提前走多少步?最后返回结果应该返回什么?
以下是代码+解析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {public : ListNode* removeNthFromEnd (ListNode* head, int n) { ListNode dummy (0 ) ; dummy.next = head; ListNode *slow = &dummy; ListNode *fast = &dummy; for (int i=0 ; i<=n; ++i) { fast = fast->next; } while (fast != nullptr ) { slow = slow->next; fast = fast->next; } ListNode *toDelete = slow->next; slow->next = toDelete->next; delete toDelete; return dummy.next; } };
[!IMPORTANT]
这里有三点:
为了防止出现指针溢出以及边界情况,我们从dummy head 出发走n步,一定是不会走出去的, 并且我们想让 slow 停在删除节点的前驱, 所以我们必须要走 n+1 步
如果我们想要让 fast 彻底走出去, 就用 fast != nullptr, 如果我们想要让 fast 停在最后一个,就用 fast->next != nullptr 这里显然是想让其走出去:直接考虑边界情况即可: [1, 2] n=2 这里fast要走 2+1 = 3 步,这个时候fast走出去了,slow停在dummy ,也就是要删除的节点1的前驱,没问题
返回值必须返回 dummy.next 而不是head,因为head也有被删的可能,参照上面的例子,所以这里注意三点就能写好代码!
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:
1 2 输入:head = [1,2,3,4] 输出:[2,1,4,3]
示例 2:
示例 3:
提示:
链表中节点的数目在范围 [0, 100] 内
0 <= Node.val <= 100
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public : ListNode* swapPairs (ListNode* head) { ListNode dummy (0 ) ; dummy.next = head; ListNode *slow = &dummy; ListNode *fast = &dummy; while (fast->next != nullptr && fast->next->next != nullptr ) { fast = fast->next->next; ListNode *first = slow->next; ListNode *second = fast; slow->next = second; first->next = second->next; second->next = first; slow = fast = first; } return dummy.next; } };
[!IMPORTANT]
这里关键点在于:
while 里面 快指针这俩判断条件还是不要忘记!(如果 fast 要走两步,这两个条件都不能少!)
由于执行了交换,我们想移动slow使得slow = fast 也就是指向的节点是下一组第一个的前驱节点,所以 slow = fast = first 而不是 second!















 wechat
wechat alipay
alipay